环境准备
【如果你的是Windows】
则需要按照官方的教程准备Anaconda环境:
https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/environment.html#11-windows
【如果你的是Linux】
则有两种选择:
方法一,安装Anaconda环境:
https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/environment.html#131-anaconda
方法二,使用现成的Docker环境(注意更换paddle的版本,因为官方的命令有误):
https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/environment.html#132-docker
那针对Linux的方法二,可以参考以下命令创建docker容器:
#首先切换到你的工作路径,然后执行以下命令 #注意:$PWD:/paddle的意思是将容器的/paddle路径映射到宿主机的当前目录中,因此建议运行前先想好要映射到哪个位置,从而提前切换到对应的路径 #如果用CPU环境中使用docker,则用这个命令 sudo docker run --name ppocr -v $PWD:/paddle --network=host -it paddlepaddle/paddle:3.0.0rc1 /bin/bash
如果需要其他版本的docker,请到该链接中进行查找:
https://hub.docker.com/r/paddlepaddle/paddle/tags/
如果用GPU环境中使用docker,则根据你的CUDA和CUDNN版本来选择你所需要的docker镜像,但记得要设置显存大小(–shm-size),命令参考如下:
#如果用GPU(cuda10.2+cudnn7)环境中使用docker,则用这个命令 sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash #如果用GPU(cuda11.2+cudnn8)环境中使用docker,则用这个命令 sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-gpu-cuda11.2-cudnn8 /bin/bash
再次进入容器可以使用如下命令:
sudo docker container exec -it ppocr /bin/bash
启动容器可以使用如下命令:
docker start ppocr
删除容器可以使用如下命令:
sudo docker rm ppocr
快速开始
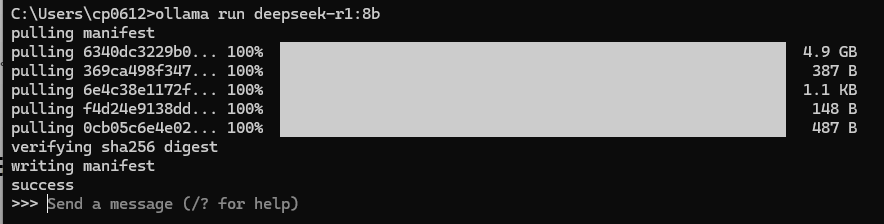
由于使用Docker环境部署的话, Docker已经包含了paddlepaddle环境,我们可以直接安装paddleocr:
pip install paddleocr
然后运行以下指令以查看paddleorc是否能正常运作:
paddleocr -h
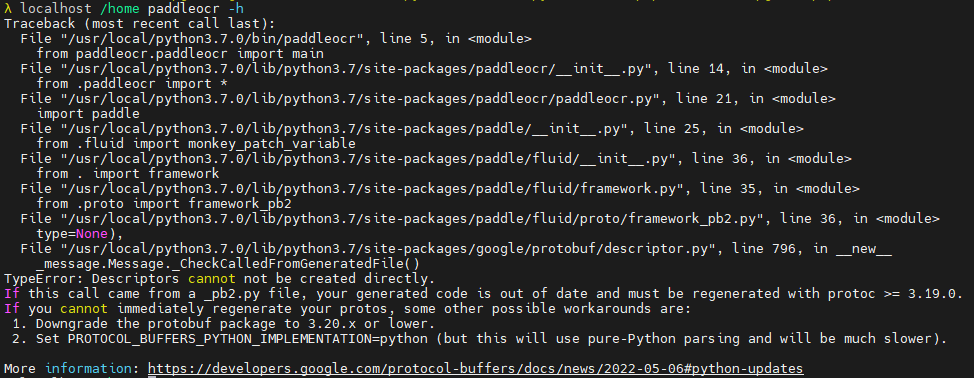
PaddleOCR 依赖的
protobuf 版本需 ≤3.20.x,新版(≥4.0)因协议不兼容会报错。通过降级
protobuf 或调整环境变量可绕过此问题。因此需要执行以下命令将protobuf降到兼容版本:
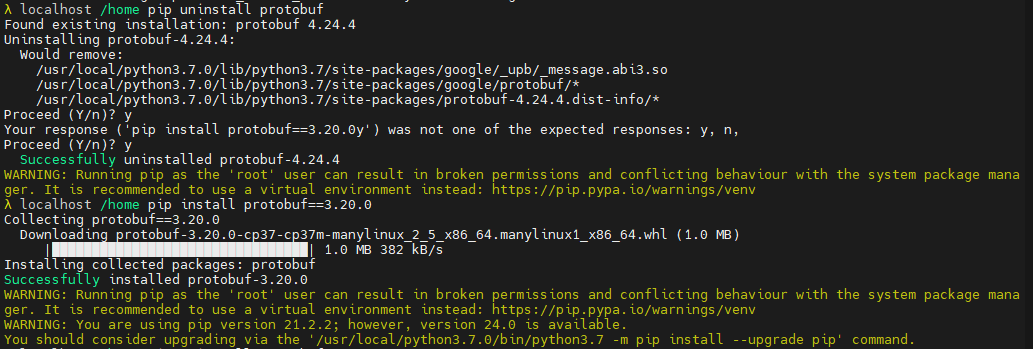
#卸载原有的protobuf pip uninstall protobuf #安装指定版本的protobuf pip install protobuf==3.20.0
然后再使用“paddleocr -h”指令检查是否正常运行paddleocr:
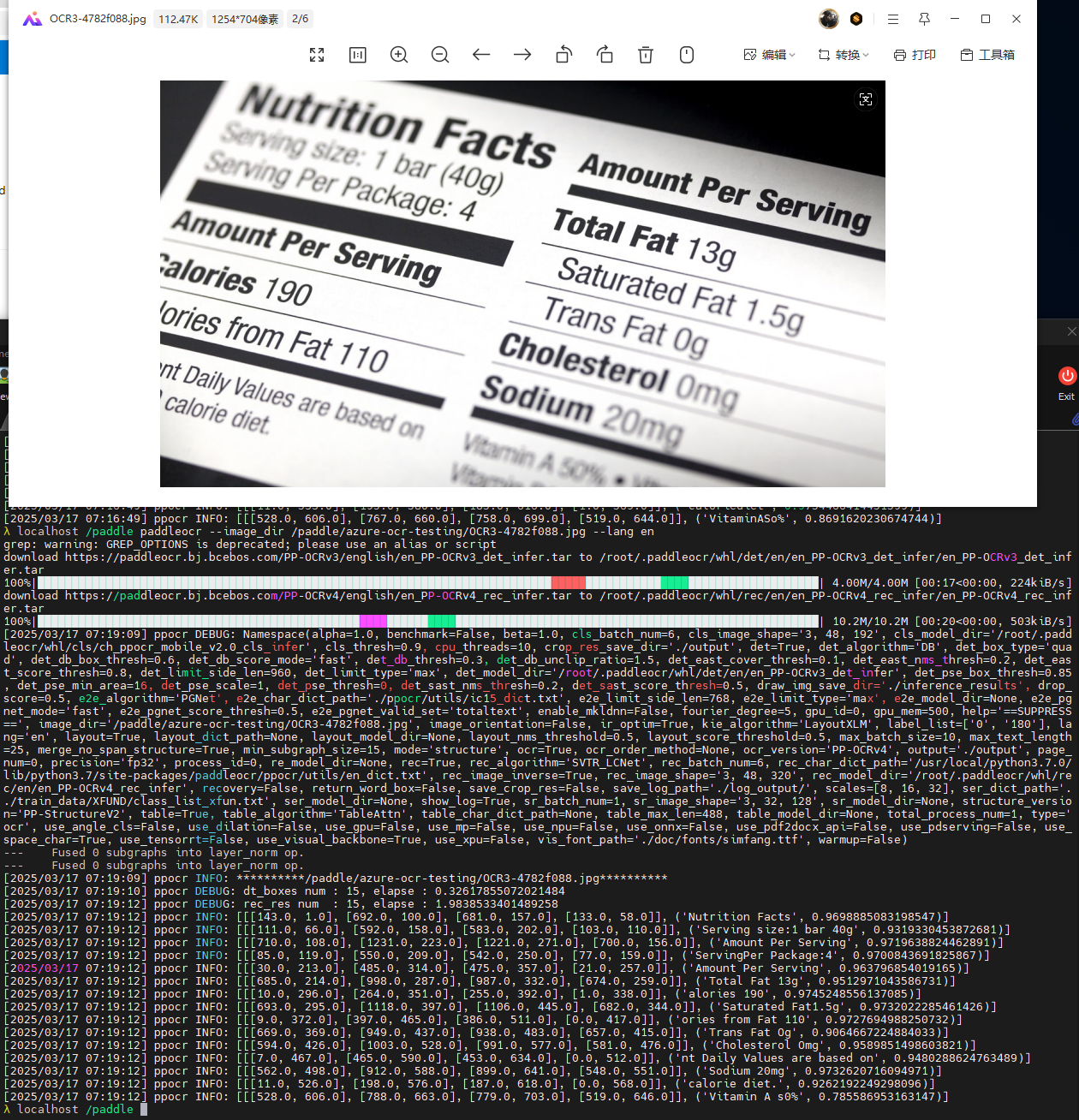
接下来使用如下命令尝试将图片转文字:
#首次运行需要下载大模型,模型的默认下载位置是:${HOME}/.paddleocr
#如需更改模型的存储位置,可设置环境变量:PADDLE_OCR_BASE_DIR
#目前语言可选:'ch', 'en', 'korean', 'japan', 'chinese_cht', 'ta', 'te', 'ka', 'latin', 'arabic', 'cyrillic', 'devanagari'
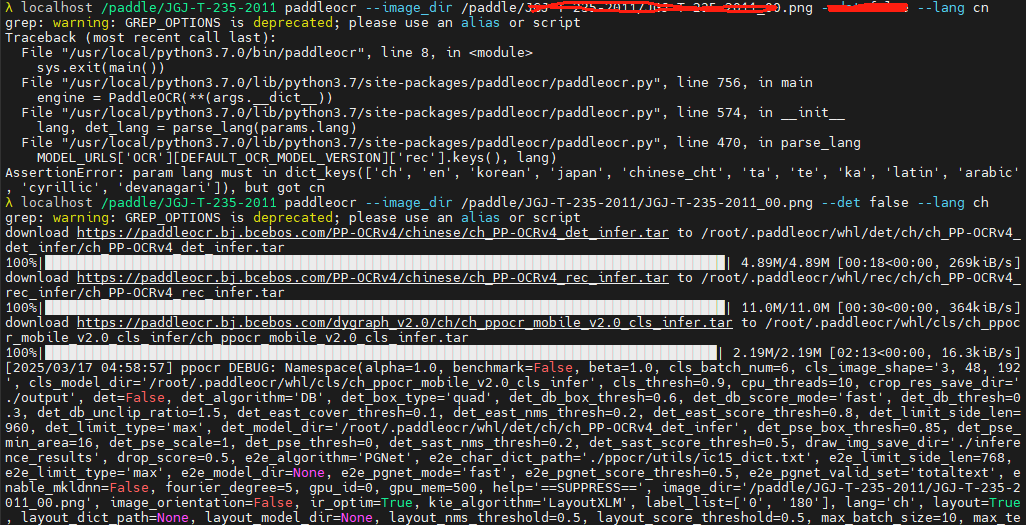
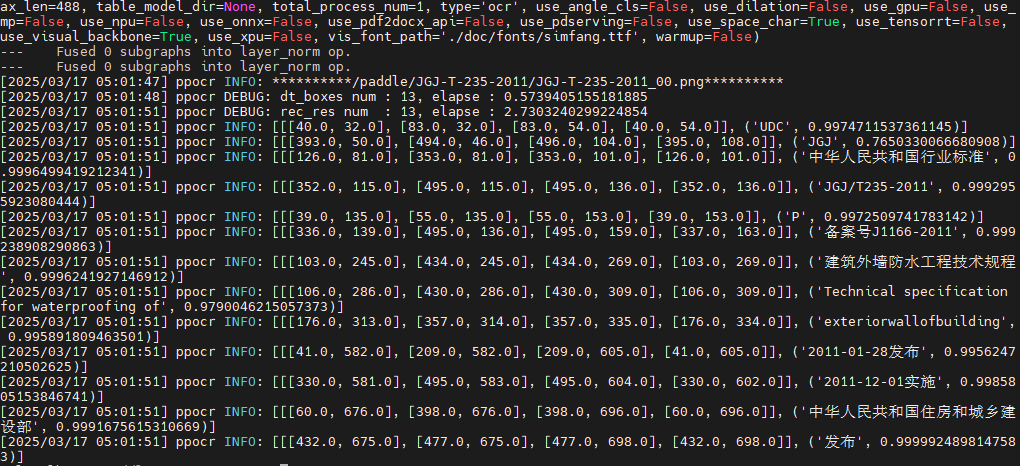
paddleocr --image_dir /paddle/JGJ-T-235-2011/JGJ-T-235-2011_00.png --lang ch
如果需要识别PDF,则需要提前安装PyMuPDF,命令如下:
pip install PyMuPDF
注意:请务必阅读PyMuPDF的开源协议。相关链接如下: