本人转载并修改于原文《ingress-nginx详解和部署方案》,出处:https://blog.csdn.net/weixin_44729138/article/details/105978555
在此先感谢原作者的奉献。
1、ingress介绍
K8s集群对外暴露服务的方式目前只有三种:
Loadblancer;Nodeport;ingress
前两种熟悉起来比较快,而且使用起来也比较方便,在此就不进行介绍了。
下面详细讲解下ingress这个服务,ingress由两部分组成:
ingress controller:将新加入的Ingress转化成Nginx的配置文件并使之生效
ingress服务:将Nginx的配置抽象成一个Ingress对象,每添加一个新的服务只需写一个新的Ingress的yaml文件即可
其中ingress controller目前主要有两种:基于nginx服务的ingress controller和基于traefik的ingress controller。
而其中traefik的ingress controller,目前支持http和https协议。由于对nginx比较熟悉,而且需要使用TCP负载,所以在此我们选择的是基于nginx服务的ingress controller。
但是基于nginx服务的ingress controller根据不同的开发公司,又分为k8s社区的ingres-nginx和nginx公司的nginx-ingress。
在此根据github上的活跃度和关注人数,我们选择的是k8s社区的ingres-nginx。
k8s社区提供的ingress,github地址如下:
https://github.com/kubernetes/ingress-nginx
nginx社区提供的ingress,github地址如下:
https://github.com/nginxinc/kubernetes-ingress
2、ingress的工作原理
ingress具体的工作原理如下:
step1:ingress contronler通过与k8s的api进行交互,动态的去感知k8s集群中ingress服务规则的变化,然后读取它,并按照定义的ingress规则,转发到k8s集群中对应的service。
step2:而这个ingress规则写明了哪个域名对应k8s集群中的哪个service,然后再根据ingress-controller中的nginx配置模板,生成一段对应的nginx配置。
step3:然后再把该配置动态的写到ingress-controller的pod里,该ingress-controller的pod里面运行着一个nginx服务,控制器会把生成的nginx配置写入到nginx的配置文件中,然后reload一下,使其配置生效,以此来达到域名分配置及动态更新的效果。
3、ingress可以解决的问题
1)动态配置服务
如果按照传统方式, 当新增加一个服务时, 我们可能需要在流量入口加一个反向代理指向我们新的k8s服务. 而如果用了Ingress, 只需要配置好这个服务, 当服务启动时, 会自动注册到Ingress的中, 不需要而外的操作。
2)减少不必要的端口暴露
配置过k8s的都清楚, 第一步是要关闭防火墙的, 主要原因是k8s的很多服务会以NodePort方式映射出去, 这样就相当于给宿主机打了很多孔, 既不安全也不优雅. 而Ingress可以避免这个问题, 除了Ingress自身服务可能需要映射出去, 其他服务都不要用NodePort方式。
4、部署ingress(deployment的方式)
查看当前版api版本:
kubectl explain Ingress
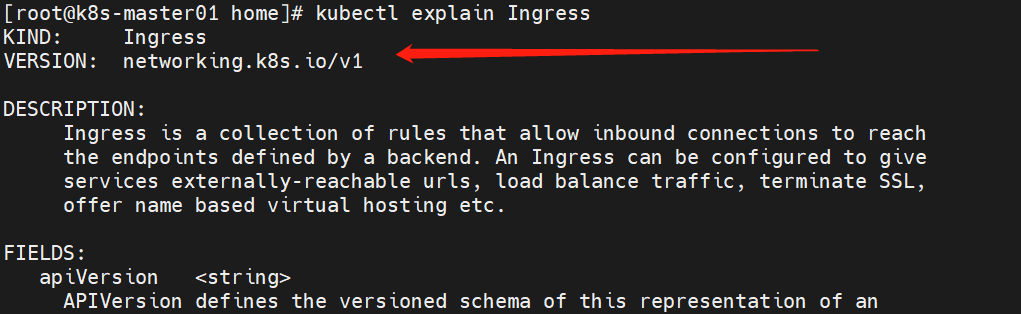
注:查看ingress和自己本地的k8s版本是否对应上,在GitHub上有表格参考。
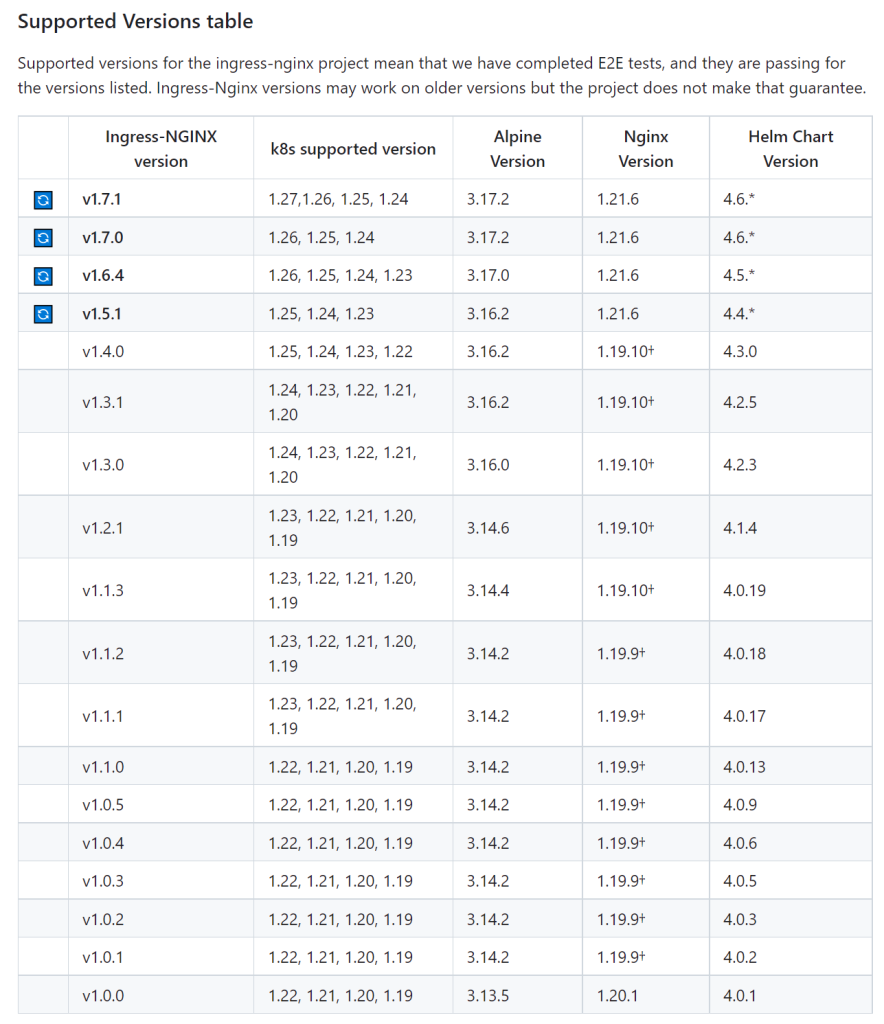
下载配置文件:
mkdir -p /root/ingress && cd /root/ingress wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.3/deploy/static/provider/baremetal/deploy.yaml
查看源:
cat deploy.yaml | grep image:
替换镜像:
sed -i 's#k8s.gcr.io/ingress-nginx/controller:v1.1.3@sha256:31f47c1e202b39fadecf822a9b76370bd4baed199a005b3e7d4d1455f4fd3fe2#registry.cn-hangzhou.aliyuncs.com/imges/controller:v1.1.3#' deploy.yaml sed -i 's#k8s.gcr.io/ingress-nginx/kube-webhook-certgen:v1.1.1@sha256:64d8c73dca984af206adf9d6d7e46aa550362b1d7a01f3a0a91b20cc67868660#registry.cn-hangzhou.aliyuncs.com/chenby/kube-webhook-certgen:v1.1.1#' deploy.yaml
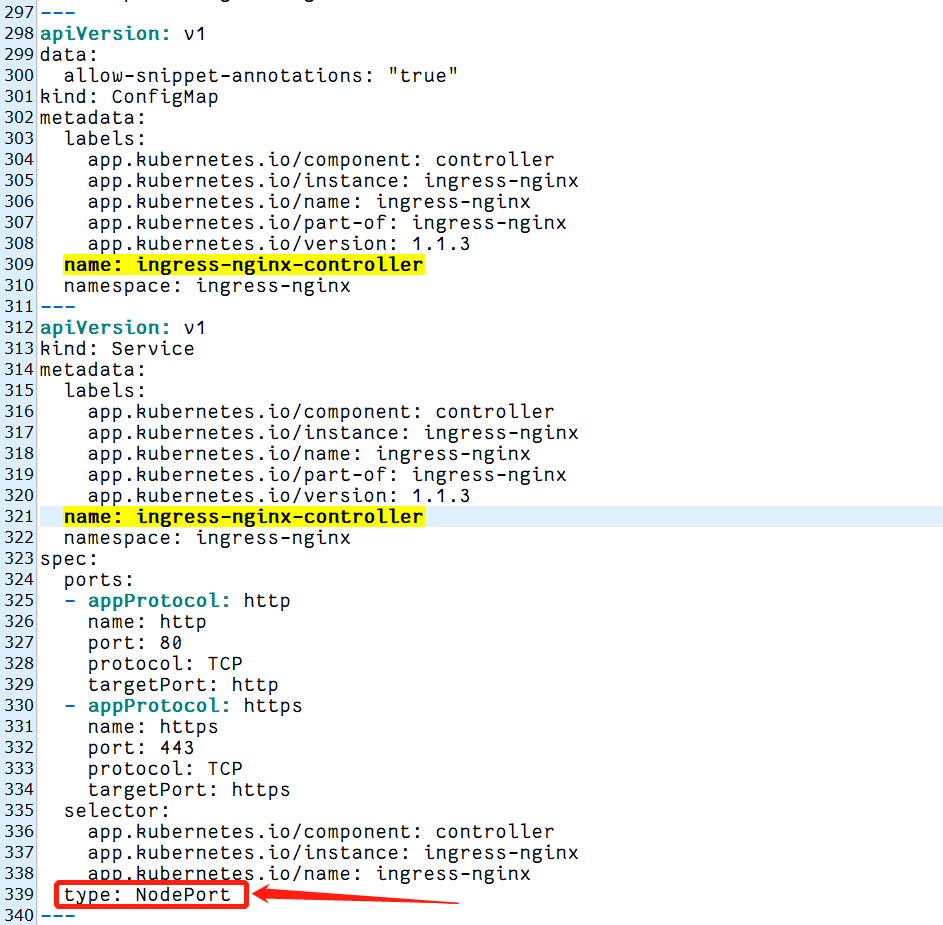
注意:有些版本的ingress-nginx的配置配置文件的type默认为LoadBalaner,需要暴露的服务其后端svc访问类型需要改成NodePort:
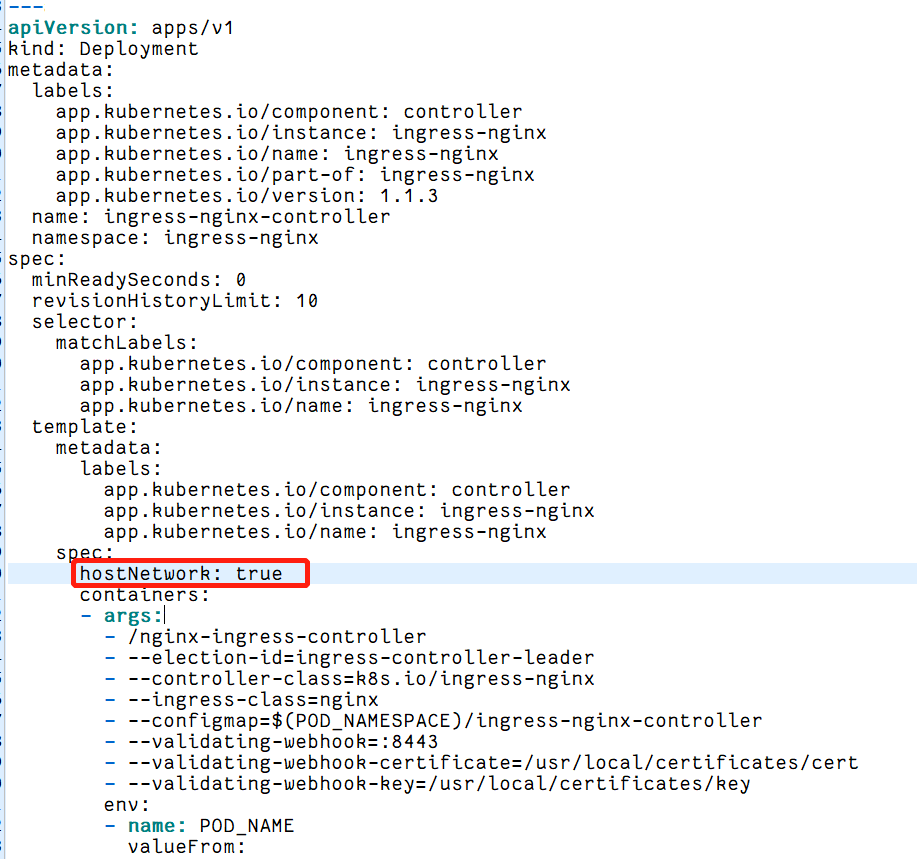
另外,ingress-controller的官方yaml默认注释了hostNetwork 工作方式,以防止端口的在宿主机的冲突,没有绑定到宿主机 80 端口,因此还要在名为ingress-nginx-controller的Deployment配置的spec下增加“hostNetwork: true”的属性:
启动POD:
kubectl apply -f deploy.yaml

查看pod运行情况:
kubectl get pod -n ingress-nginx

启动时间有点长,最终的运行结果应该是这样的:

说明:status为completed的两个pod为job类型资源,completed表示job已经成功执行无需管它。
查看svc运行情况:
kubectl get svc -n ingress-nginx

查看controller所在的工作节点:
kubectl get pods -n ingress-nginx -o wide

[root@k8s-node03 ~]# netstat -lnp|grep 80

至此,ingress-nginx部署成功。
5、启用默认后端
mkdir -p /root/ingress ; cd /root/ingress
cat > backend.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: default-http-backend
labels:
app.kubernetes.io/name: default-http-backend
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: default-http-backend
template:
metadata:
labels:
app.kubernetes.io/name: default-http-backend
spec:
terminationGracePeriodSeconds: 60
containers:
- name: default-http-backend
image: registry.cn-hangzhou.aliyuncs.com/imges/defaultbackend-amd64:1.5
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
ports:
- containerPort: 8080
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 10m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: default-http-backend
namespace: kube-system
labels:
app.kubernetes.io/name: default-http-backend
spec:
ports:
- port: 80
targetPort: 8080
selector:
app.kubernetes.io/name: default-http-backend
EOF
部署:
kubectl apply -f backend.yaml
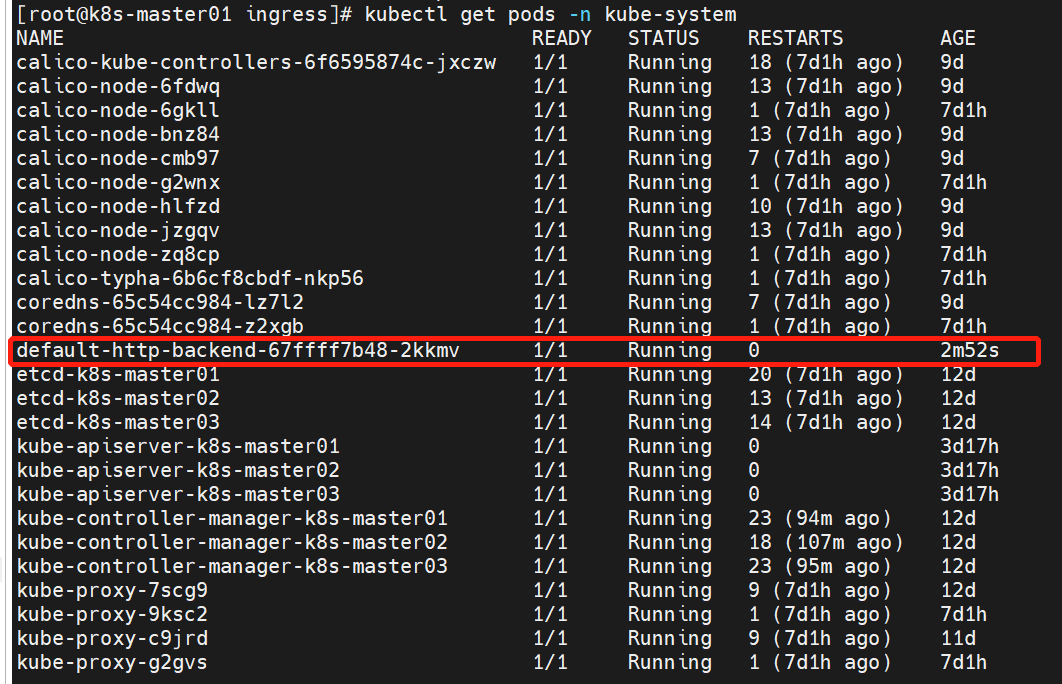
查看默认后端运行情况:
kubectl get pods -n kube-system
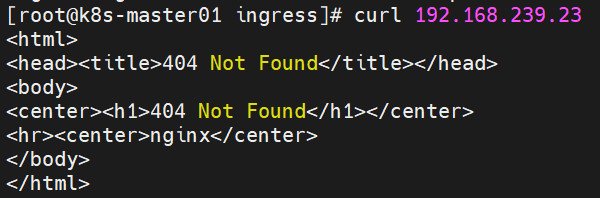
访问ingress-nginx-controller节点所在的node的80端口,看是否正确返回backend的404提示页面:
curl 192.168.239.23
6、测试
创建svc和pod:
我们使用默认的nginx镜像创建svc和pod,用于测试:
vim ingress-dev.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dm
namespace: default
spec:
replicas: 2
selector:
matchLabels:
name: nginx
template:
metadata:
labels:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.16
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: default
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
name: nginx
kubectl apply -f ingress-dev.yaml
kubectl get pod -n default -o wide

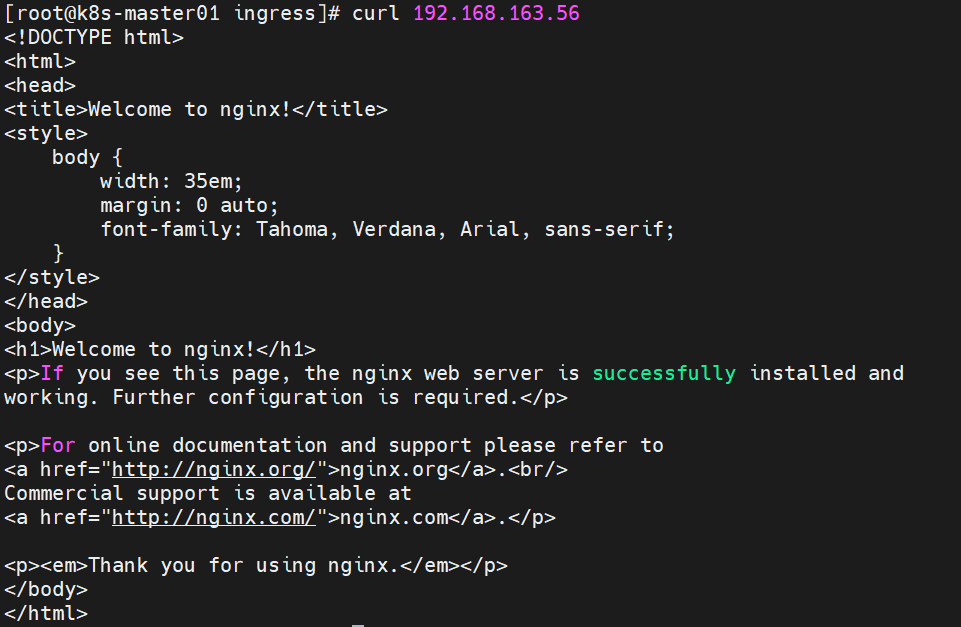
查看对应的ClusterIP:
kubectl get pods,svc -o wide

curl 192.168.163.56
配置ingress:
vim ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-test
namespace: default
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: test.sway.com.cn
http:
paths:
- path: /
pathType: Prefix # 前缀匹配
backend:
service:
name: nginx-svc
port:
number: 80
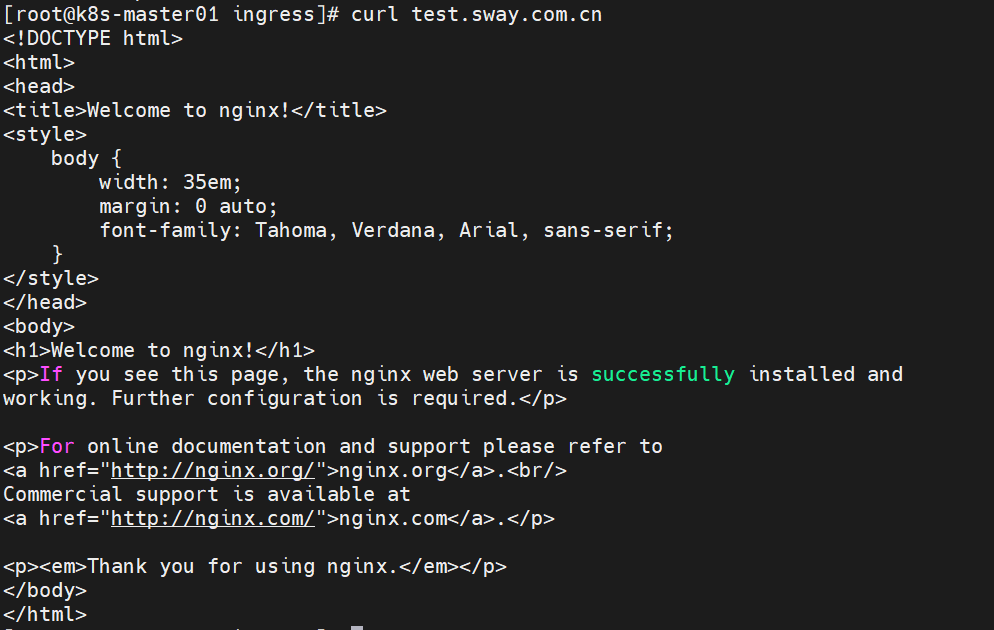
kubectl get ingress -n default

测试服务的可访问情况:
curl test.sway.com.cn
至此,所有配置完成。