使用 systemctl status keepalived 名称查看运行情况:
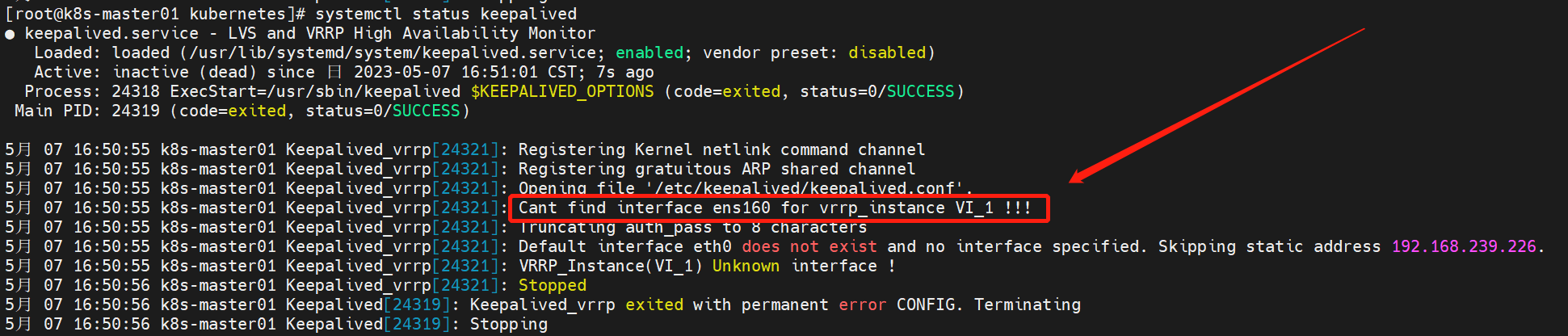
这种情况一般时keepalived配置中所指定的网卡不存在引起的。大家使用网上教程的时候要注意记得更改网卡名称,根据实际的网卡名称来进行配置。不指导网卡名称时什么的,可以使用“ip address”命令进行查看:
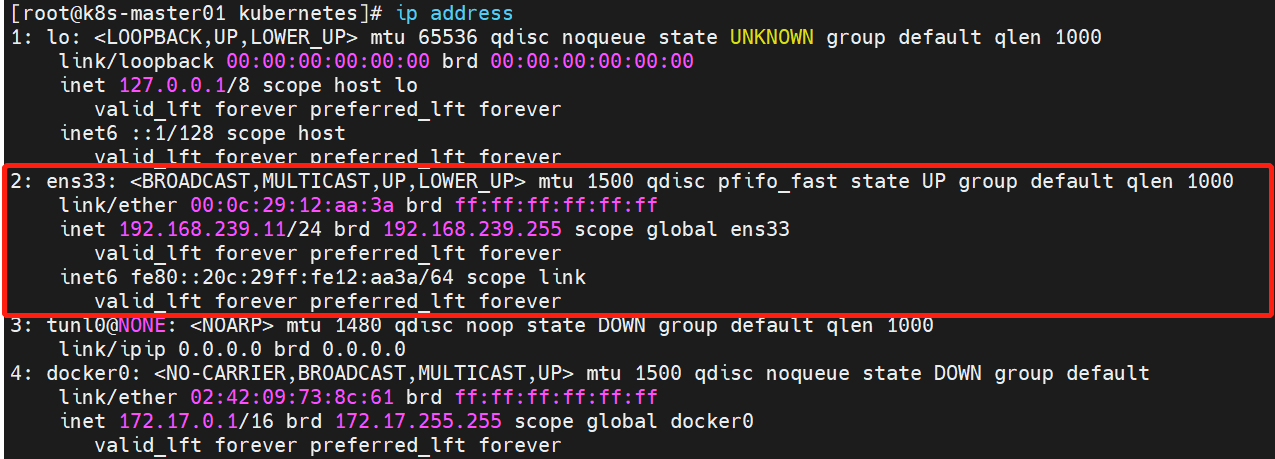
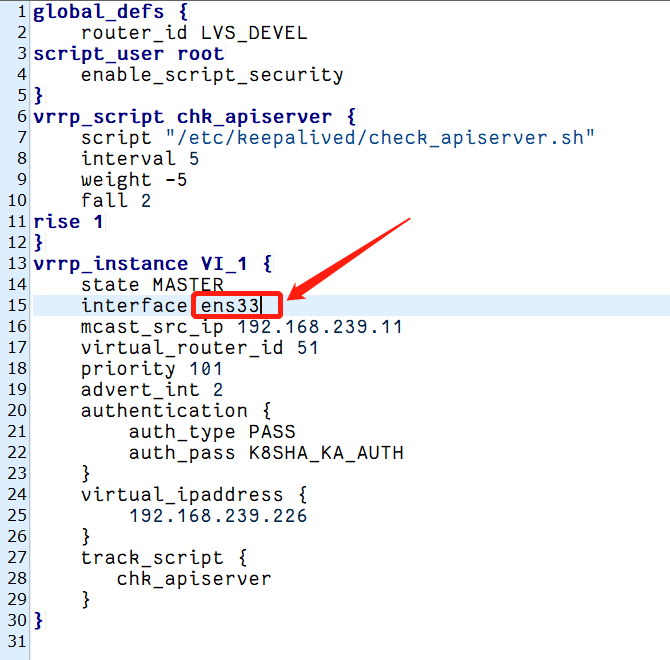
systemctl restart keepalived

使用 systemctl status keepalived 名称查看运行情况:
这种情况一般时keepalived配置中所指定的网卡不存在引起的。大家使用网上教程的时候要注意记得更改网卡名称,根据实际的网卡名称来进行配置。不指导网卡名称时什么的,可以使用“ip address”命令进行查看:
systemctl restart keepalived
Posted in 未分类
可以先使用以下命令查看k8s的启动日志:
systemctl status kubelet
或使用以下命令查看最近的k8s日志:
journalctl -xeu kubelet

所以在初始化前修改/etc/containerd/config.toml的镜像地址参数:
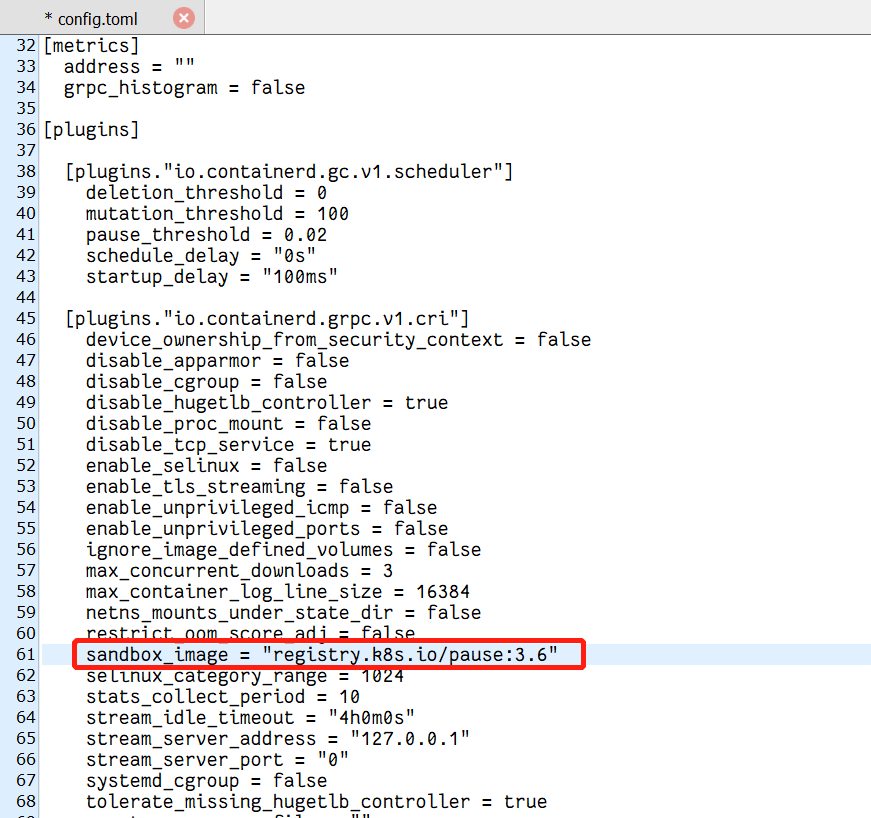
[plugins."io.containerd.grpc.v1.cri"] sandbox_image = "registry.aliyuncs.com/k8sxio/pause:3.6"
然后重启containerd:
systemctl restart containerd
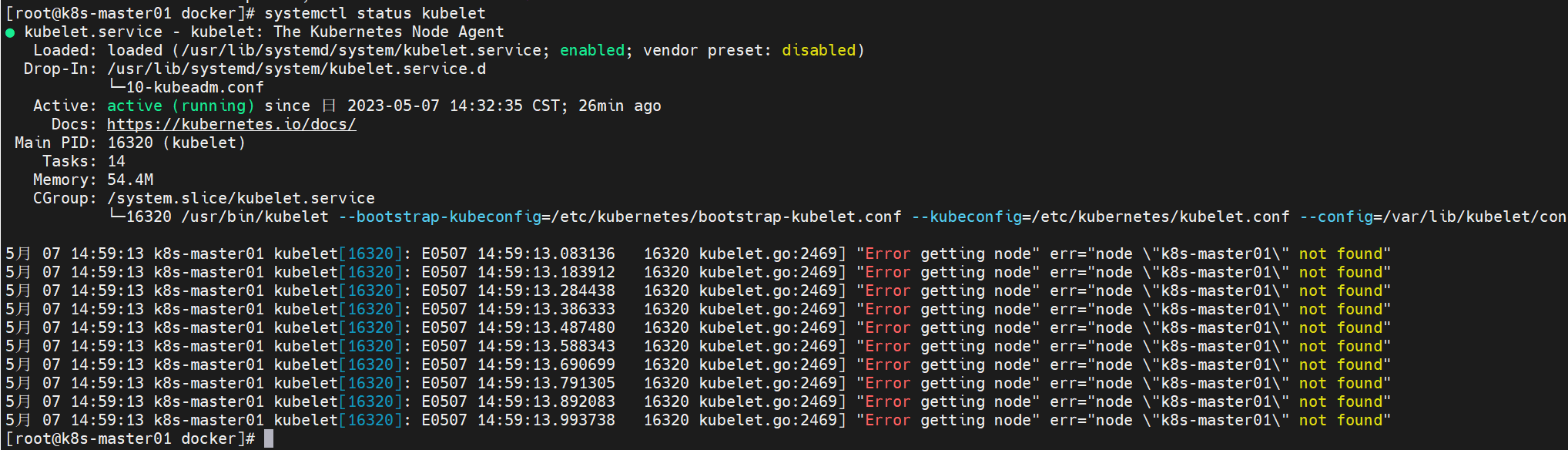
查看/var/log/messages的最后日志:
May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.071077 16320 eviction_manager.go:254] "Eviction manager: failed to get summary stats" err="failed to get node info: node \"k8s-master01\" not found" May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.096124 16320 kubelet.go:2394] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized" May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.160241 16320 kubelet.go:2469] "Error getting node" err="node \"k8s-master01\" not found" May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.262056 16320 kubelet.go:2469] "Error getting node" err="node \"k8s-master01\" not found" May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.362486 16320 kubelet.go:2469] "Error getting node" err="node \"k8s-master01\" not found" May 7 14:34:26 k8s-master01 kubelet: E0507 14:34:26.463165 16320 kubelet.go:2469] "Error getting node" err="node \"k8s-master01\" not found"
这是由于还没有安装网络插件flannel引起的。
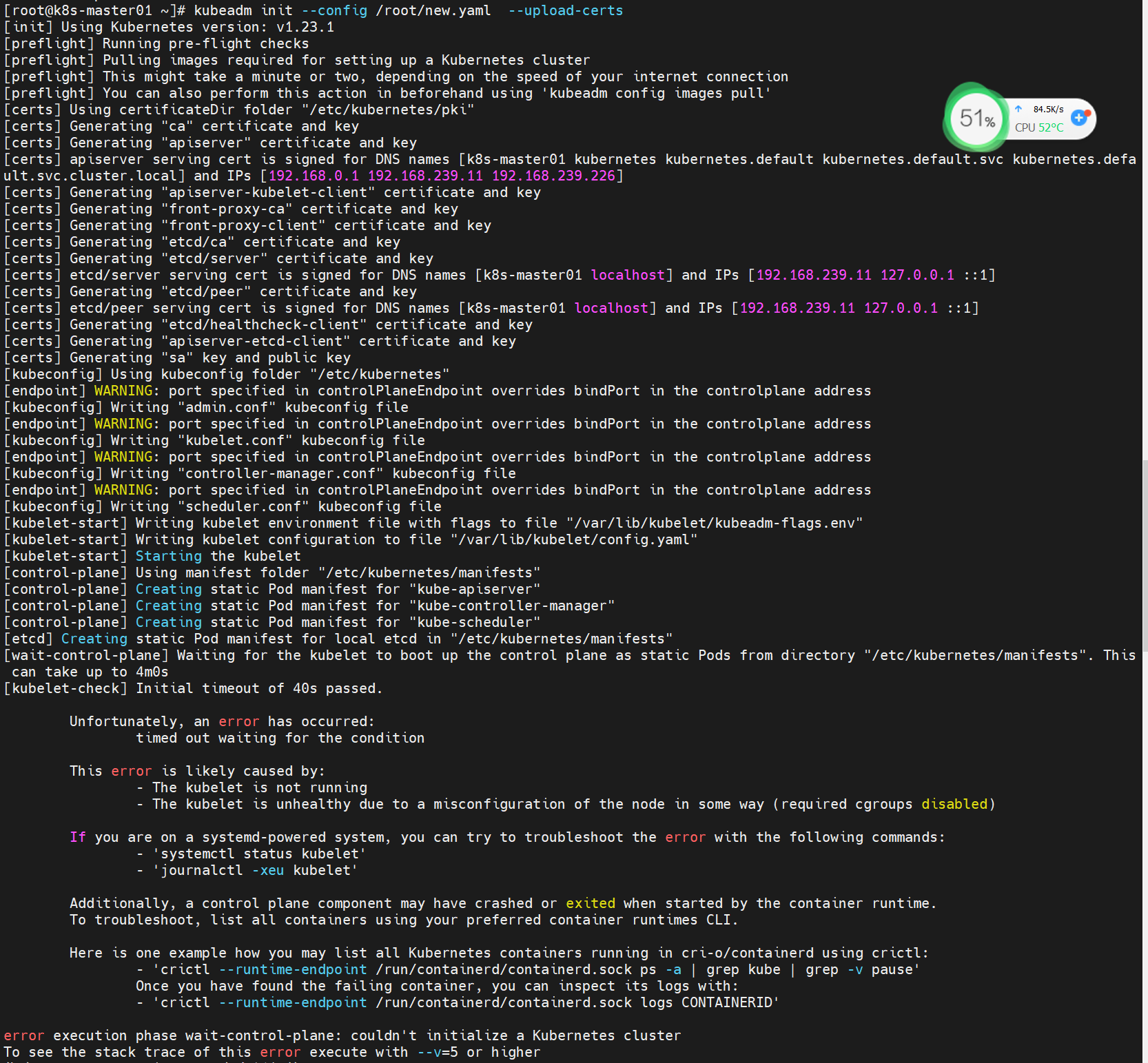
查看/var/log/messages的最后日志:
Aug 23 18:17:21 localhost kubelet: E0823 18:17:21.059626 9490 server.go:294] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\"" Aug 23 18:17:21 localhost systemd: kubelet.service: main process exited, code=exited, status=1/FAILURE Aug 23 18:17:21 localhost systemd: Unit kubelet.service entered failed state. Aug 23 18:17:21 localhost systemd: kubelet.service failed.
从日志看出来,是因为hubernates与docker的cgroup驱动不一致引起的,那么我们只需要将两者的cgroup驱动设置为一直即可。(官方推荐systemd)
我们可以用以下指令确认一下docker的启动方式:
docker system info|grep -i driver

一、找到docker的配置文件/etc/docker/daemon.json并修改添加如下参数(没有找到则新建一个):
"exec-opts": ["native.cgroupdriver=systemd"]
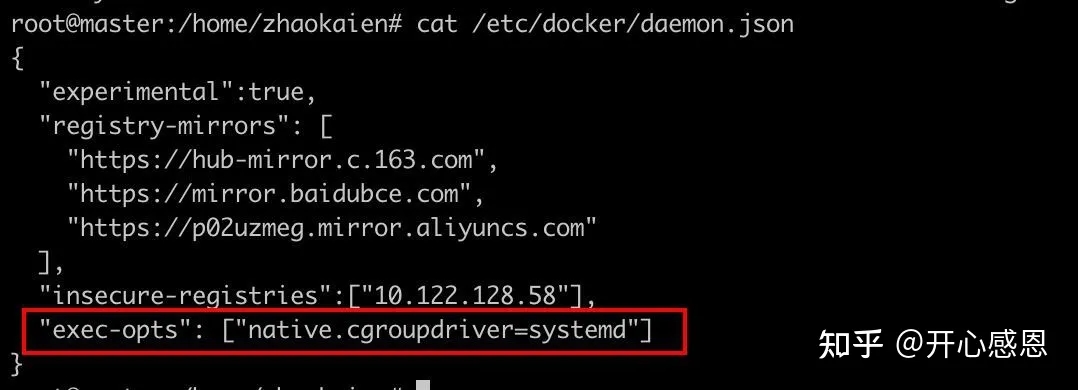
二、重启docker,并再次检查docker的驱动是否已经变更:
systemctl restart docker docker system info|grep -i driver

有两个文件:
一、/etc/sysconfig/kubelet
增加参数–cgroup-driver=systemd:

二、修改10-kubeadm.conf文件(使用该指令查找:find / -name ’10-kubeadm.conf’)
增加参数–cgroup-driver=systemd:
然后重启kubernates服务即可:
systemctl restart kubelet
最后,重置kubeamdm并再次执行k8s初始化指令即可:
kubeadm reset
Posted in 未分类