
第一步:Ollama的下载、安装、运行
到这个网站下载并安装:https://ollama.com/
安装完成并运行后,任务栏的右下角会有如下图标:
第二步:下载并运行DeepSeek模型
进入Ollama的这个网址可以查看到DeepSeek-R1有哪些模型可以直接下载并使用:
https://ollama.com/library/deepseek-r1
然后使用如下命令下载并运行模型:
(注意:Ollama默认的模型下载位置是系统当前登录用户的文件空间中,所以多数情况是放在C盘,请先确保有足够的存储空间。如果需要更改,请在系统中设置系统变量“OLLAMA_MODELS”,值为你要用于存放模型的文件夹路径。设置后,需要重启Ollama才会生效。)
ollama run deepseek-r1:7b
7b是模型的类型,请根据自己的需求进行调整。
“B”代表“Billion”,即“十亿”。这是用来量度模型中参数的数量。
——傻瓜式判断你应该使用哪种——-
1.5B 模型:4GB 显存
7B、8B 模型:8GB 显存
14B 模型:12GB 显存
32B 模型:24GB 显存
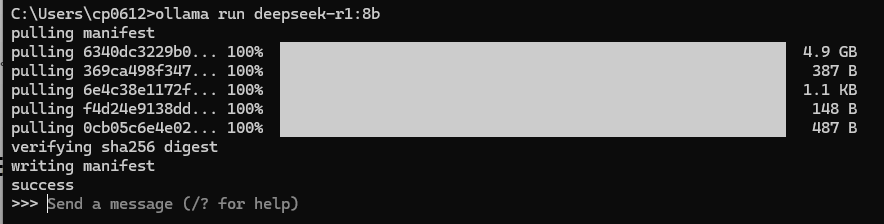
下载成功后会自动运行,出现>>>的符号表示你此时可以输入文字跟AI对话了:

第三步:设置模型推理时使用CPU还是GPU(可选)
刚刚装好,跟AI对话的时候发现AI的回复很慢,怎么跟网上的响应速度差那么远?我的电脑是12代I5,3050的显卡,理论上使用7b应该是轻松应付的。于是查了一下资料得知我们现在只是使用AI模型进行推理,而并非训练,因此推理的话,使用CPU或是GPU都是可以的。而Ollama在装好后,可能默认使用的是CPU进行推理。怎么去判断呢?
如果是Nvidia的显卡,可以在AI模型正在回复的时候使用nvidia-smi命令来查看是否有ollama的进程在运行:

如果是其他显卡就不知道了。但是我们可以在CMD夏直接使用以下命令进行配置:
export CUDA_VISIBLE_DEVICES=0 # 指定使用第一个 GPU
配置好后,记得重启Ollama服务,以让配置生效。
经过测试,速度立刻变得飞快。
那也顺便给大家配置回去CPU推理的命令:
export CUDA_VISIBLE_DEVICES="" # 清空变量,强制使用 CPU