用JDK8用了差不多十年了,也该更新一下了,毕竟SpringBoot3系列已经不再支持JDK8了,所以本次的整合是基于JDK17的。
SpringBoot3.1.2整合Security时,Security的默认版本为6.1.2。
废话不多说,直接上代码。
(response.write封装我不贴了,这种基础代码自己解决就好)
依赖:pom.xml:
<!--spring security 启动器-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.xml.bind/jaxb-api -->
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
<!--jwt-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.0</version>
</dependency>
<!-- mybatis -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>3.0.0</version>
</dependency>
<!-- mysql -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!--redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置文件application.yml:
server:
port: 8080
spring:
# 数据源配置
datasource:
url: jdbc:mysql://localhost:3306/hkbea-gbt?useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# mybatis配置
mybatis:
# 配置SQL映射文件路径
mapper-locations: classpath:/mapper/*.xml
# 实体类别名包扫描(请更换成实际的)
type-aliases-package: **.**.**.**
# 驼峰命名
configuration:
map-underscore-to-camel-case: true
token异常处理类:AuthenticationEntryPointImpl.java
import com.fasterxml.jackson.databind.ObjectMapper;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.security.core.AuthenticationException;
import org.springframework.security.web.AuthenticationEntryPoint;
import org.springframework.stereotype.Component;
import java.io.IOException;
/**
* 认证失败
*/
@Component
public class AuthenticationEntryPointImpl implements AuthenticationEntryPoint {
@Override
public void commence(HttpServletRequest request, HttpServletResponse response, AuthenticationException authException) throws IOException {
response.setContentType("application/json;charset=UTF-8");
response.getWriter().println("无效登录信息");
}
}
permission异常处理类:AccessDeniedHandlerImpl.java import com.fasterxml.jackson.databind.ObjectMapper;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.security.access.AccessDeniedException;
import org.springframework.security.web.access.AccessDeniedHandler;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
public class AccessDeniedHandlerImpl implements AccessDeniedHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, AccessDeniedException accessDeniedException) throws IOException {
response.setContentType("application/json;charset=UTF-8");
response.getWriter().println("你无权进行本操作");
}
}
核心配置类:SecurityConfig.java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.config.annotation.authentication.configuration.AuthenticationConfiguration;
import org.springframework.security.config.annotation.method.configuration.EnableMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;
/**
* SpringSecurity 核心配置类
* prePostEnabled = true 开启注解权限认证功能
*/
@Configuration
@EnableWebSecurity
@EnableMethodSecurity
public class SecurityConfig {
@Autowired
private AuthenticationConfiguration authenticationConfiguration;
//认证过滤器
@Autowired
private JwtAuthenticationTokenFilter jwtAuthenticationTokenFilter;
// 认证失败处理器
@Autowired
private AuthenticationEntryPointImpl authenticationEntryPoint;
// 授权失败处理器
@Autowired
private AccessDeniedHandlerImpl accessDeniedHandler;
/**
* 认证配置
* anonymous():匿名访问:未登录可以访问,已登录不能访问
* permitAll():有没有认证都能访问:登录或未登录都能访问
* denyAll(): 拒绝
* authenticated():认证之后才能访问
* hasAuthority():包含权限
*/
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
// 允许跨域(也可以不允许,一般前后端分离项目要关闭此功能)
.cors()
//关闭csrf:为了防止通过伪造用户请求来访问受信用站点的非法请求访问
.and()
.csrf().disable();
http
.anonymous().disable() //禁用anonymous用户(影响Authentication.getPrincipal()的返回):disable=>匿名用户的authentication为null
// 禁用session (前后端分离项目,不通过Session获取SecurityContext)
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS)
//登录配置 //此处全部注释,在本案例中采用注解进行权限拦截
//.and()
// 添加token过滤器
//.apply(permitAllSecurityConfig)
//.and()
// 配置路径是否需要认证
//.authorizeHttpRequests()
//配置放行资源(注意: 放行资源必须放在所有认证请求之前!)
//.requestMatchers("/api/v1/auth/login").permitAll()
//.requestMatchers("/api/v1/auth/register").permitAll()
//.requestMatchers("/api/v1/on1on/**").permitAll()
//.requestMatchers("/api/v1/admin/**").hasAuthority("admin") // 对于admin接口 需要权限admin
// 除上面外的所有请求全部需要鉴权认证
//.anyRequest().authenticated() //代表所有请求,必须认证之后才能访问
//.anyRequest().permitAll()
.and()
.authenticationManager(authenticationManager(authenticationConfiguration))
.sessionManagement()
.sessionCreationPolicy(SessionCreationPolicy.STATELESS).and()
//此处为添加jwt过滤
.addFilterBefore(jwtAuthenticationTokenFilter, UsernamePasswordAuthenticationFilter.class)
;
// 配置异常处理器
http.exceptionHandling()
// 认证失败
.authenticationEntryPoint(authenticationEntryPoint)
// 授权失败
.accessDeniedHandler(accessDeniedHandler);
http.headers().frameOptions().disable();
return http.build();
}
/**
* 注入AuthenticationManager 进行用户认证(基于用户名和密码或使用用户名和密码进行身份验证)
* @param authenticationConfiguration
* @return
* @throws Exception
*/
@Bean
public AuthenticationManager authenticationManager(AuthenticationConfiguration authenticationConfiguration) throws Exception {
return authenticationConfiguration.getAuthenticationManager();
}
/**
* 提供密码机密处理机制:
* 将BCryptPasswordEncoder对象注入到spring容器中,更换掉原来的 PasswordEncoder加密方式
* 原PasswordEncoder密码格式为:{id}password。它会根据id去判断密码的加密方式。
* 如果没替换原来的加密方式,数据库中想用明文密码做测试,将密码字段改为{noop}123456这样的格式
*/
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}
RBAC中的Account.java:
import lombok.Data;
import java.io.Serializable;
@Data
public class Account implements Serializable {
private String id;
private String username;
private String password;
private String nickname;
}
RBAC中的AccountDao:AccountDao.java
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
@Mapper
public interface AccountDao {
/**
* 获取用户信息
*/
@Select("select * from account where username = #{username}")
Account getUserInfo(String username);
}
RBAC中的AccountService接口:AccountService.java
public interface AccountService {
/**
* 根据用户名获取用户信息
*/
Account getUserInfo(String username);
}
RBAC中的AccountService接口实现类:AccountServiceImpl.java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class AccountServiceImpl implements AccountService {
@Autowired
private AccountDao accountDao;
/**
* 根据用户名获取用户信息
*/
@Override
public Account getUserInfo(String username) {
return accountDao.getUserInfo(username);
}
}
RBAC中的权限查询类:AuthDao.java
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
import java.util.Map;
@Mapper
public interface AuthDao {
List<Map<String,Object>> getRolesAndPermissionsByAccountId(String id);
}
RBAC中的权限查询Mapper:AuthMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.hkbea.gbt.dao.AuthDao">
<!--通过手机号查找用户权限信息-->
<select id="getRolesAndPermissionsByAccountId" resultType="java.util.HashMap" parameterType="String">
SELECT role.name AS role, permission.name AS permission
FROM role,
permission,
account_role,
role_permission
WHERE account_role.account_id=#{id}
AND account_role.role_id=role.id
AND role_permission.role_id=role.id
AND role_permission.permission_id=permission.id
</select>
</mapper>
SpringSecurity核心的用户类:LoginUser.java import com.alibaba.fastjson2.annotation.JSONField;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.extern.log4j.Log4j2;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Map;
/**
* 重写UserDetails返回的用户信息
* SpringSecurity返回的用户信息实体类
*/
@Log4j2
@Data
@NoArgsConstructor
public class LoginUser implements UserDetails {
private Account account; //用户信息
private List<Map<String,Object>> rolesAndPermissions; //角色信息
private List<String> roles; //角色信息
private List<String> permissions; //权限信息
public LoginUser(Account account, List<Map<String,Object>> rolesAndPermissions) {
this.account = account;
this.roles = new ArrayList<>();
this.permissions = new ArrayList<>();
for (Map<String,Object> map : rolesAndPermissions){
log.info(map);
log.info("role : {}",map.get("role"));
this.roles.add((String)map.get("role"));
log.info("permission : {}",map.get("permission"));
this.permissions.add((String)map.get("permission"));
}
}
@JSONField(serialize = false) //fastjson注解,表示此属性不会被序列化,因为SimpleGrantedAuthority这个类型不能在redis中序列化
private List<SimpleGrantedAuthority> authorities;
/**
* 获取权限信息
*/
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
// 权限为空的时候才往遍历,不为空直接返回
if (authorities != null) {
return authorities;
}
//把permissions中String类型的权限信息封装成SimpleGrantedAuthority对象
authorities = new ArrayList<>();
for (String permission : permissions) {
SimpleGrantedAuthority authority = new SimpleGrantedAuthority(permission);
authorities.add(authority);
}
return authorities;
}
/**
* 获取密码
*/
@Override
public String getPassword() {
return account.getPassword();
}
/**
* 获取用户名
*/
@Override
public String getUsername() {
return account.getUsername();
}
/**
* 判断是否过期(账户是否未过期,过期无法验证)
*/
@Override
public boolean isAccountNonExpired() {
return true;
}
/**
* 是否锁定(指定用户是否解锁,锁定的用户无法进行身份验证)
*/
@Override
public boolean isAccountNonLocked() {
return true;
}
/**
* 是否没有超时(指示是否已过期的用户的凭据(密码),过期的凭据防止认证)
*/
@Override
public boolean isCredentialsNonExpired() {
return true;
}
/**
* 是否可用(用户是否被启用或禁用。禁用的用户无法进行身份验证。)
*/
@Override
public boolean isEnabled() {
return true;
}
}
Redis使用FastJson序列化的相关类:FastJsonRedisSerializer.java
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.parser.ParserConfig;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.fasterxml.jackson.databind.JavaType;
import com.fasterxml.jackson.databind.type.TypeFactory;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
import java.nio.charset.Charset;
/**
* Redis使用FastJson序列化
*/
public class FastJsonRedisSerializer<T> implements RedisSerializer<T> {
public static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8");
private Class<T> clazz;
static {
ParserConfig.getGlobalInstance().setAutoTypeSupport(true);
}
public FastJsonRedisSerializer(Class<T> clazz) {
super();
this.clazz = clazz;
}
@Override
public byte[] serialize(T t) throws SerializationException {
if (t == null) {
return new byte[0];
}
return JSON.toJSONString(t, SerializerFeature.WriteClassName).getBytes(DEFAULT_CHARSET);
}
@Override
public T deserialize(byte[] bytes) throws SerializationException {
if (bytes == null || bytes.length <= 0) {
return null;
}
String str = new String(bytes, DEFAULT_CHARSET);
return JSON.parseObject(str, clazz);
}
protected JavaType getJavaType(Class<?> clazz) {
return TypeFactory.defaultInstance().constructType(clazz);
}
}
Redis配置类:RedisConfig.java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* redis配置类
* 避免存入redis中的key看上去乱码的现象
*/
@Configuration
public class RedisConfig {
@Bean
@SuppressWarnings(value = {"unchecked", "rawtypes"})
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
//使用FastJsonRedisSerializer来序列化和反序列化redis的value值
FastJsonRedisSerializer serializer = new FastJsonRedisSerializer(Object.class);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}
Redis工具类:RedisCache.java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.BoundSetOperations;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Component;
import java.util.*;
import java.util.concurrent.TimeUnit;
/**
* redis工具类
*/
@Component
public class RedisCache {
@Autowired
public RedisTemplate redisTemplate;
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
*/
public <T> void setCacheObject(final String key, final T value) {
redisTemplate.opsForValue().set(key, value);
}
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
* @param timeout 时间
* @param timeUnit 时间颗粒度
*/
public <T> void setCacheObject(final String key, final T value, final Integer timeout, final TimeUnit timeUnit) {
redisTemplate.opsForValue().set(key, value, timeout, timeUnit);
}
/**
* 设置有效时间
*
* @param key Redis键
* @param timeout 超时时间
* @return true=设置成功;false=设置失败
*/
public boolean expire(final String key, final long timeout) {
return expire(key, timeout, TimeUnit.SECONDS);
}
/**
* 设置有效时间
*
* @param key Redis键
* @param timeout 超时时间
* @param unit 时间单位
* @return true=设置成功;false=设置失败
*/
public boolean expire(final String key, final long timeout, final TimeUnit unit) {
return redisTemplate.expire(key, timeout, unit);
}
/**
* 获得缓存的基本对象。
*
* @param key 缓存键值
* @return 缓存键值对应的数据
*/
public <T> T getCacheObject(final String key) {
ValueOperations<String, T> operation = redisTemplate.opsForValue();
return operation.get(key);
}
/**
* 删除单个对象
*
* @param key
*/
public boolean deleteObject(final String key) {
return redisTemplate.delete(key);
}
/**
* 删除集合对象
*
* @param collection 多个对象
* @return
*/
public long deleteObject(final Collection collection) {
return redisTemplate.delete(collection);
}
/**
* 缓存List数据
*
* @param key 缓存的键值
* @param dataList 待缓存的List数据
* @return 缓存的对象
*/
public <T> long setCacheList(final String key, final List<T> dataList) {
Long count = redisTemplate.opsForList().rightPushAll(key, dataList);
return count == null ? 0 : count;
}
/**
* 获得缓存的list对象
*
* @param key 缓存的键值
* @return 缓存键值对应的数据
*/
public <T> List<T> getCacheList(final String key) {
return redisTemplate.opsForList().range(key, 0, -1);
}
/**
* 缓存Set
*
* @param key 缓存键值
* @param dataSet 缓存的数据
* @return 缓存数据的对象
*/
public <T> BoundSetOperations<String, T> setCacheSet(final String key, final Set<T> dataSet) {
BoundSetOperations<String, T> setOperation = redisTemplate.boundSetOps(key);
Iterator<T> it = dataSet.iterator();
while (it.hasNext()) {
setOperation.add(it.next());
}
return setOperation;
}
/**
* 获得缓存的set
*
* @param key
* @return
*/
public <T> Set<T> getCacheSet(final String key) {
return redisTemplate.opsForSet().members(key);
}
/**
* 缓存Map
*
* @param key
* @param dataMap
*/
public <T> void setCacheMap(final String key, final Map<String, T> dataMap) {
if (dataMap != null) {
redisTemplate.opsForHash().putAll(key, dataMap);
}
}
/**
* 获得缓存的Map
*
* @param key
* @return
*/
public <T> Map<String, T> getCacheMap(final String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* 往Hash中存入数据
*
* @param key Redis键
* @param hKey Hash键
* @param value 值
*/
public <T> void setCacheMapValue(final String key, final String hKey, final T value) {
redisTemplate.opsForHash().put(key, hKey, value);
}
/**
* 获取Hash中的数据
*
* @param key Redis键
* @param hKey Hash键
* @return Hash中的对象
*/
public <T> T getCacheMapValue(final String key, final String hKey) {
HashOperations<String, String, T> opsForHash = redisTemplate.opsForHash();
return opsForHash.get(key, hKey);
}
/**
* 删除Hash中的数据
*
* @param key
* @param hkey
*/
public void delCacheMapValue(final String key, final String hkey) {
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.delete(key, hkey);
}
/**
* 获取多个Hash中的数据
*
* @param key Redis键
* @param hKeys Hash键集合
* @return Hash对象集合
*/
public <T> List<T> getMultiCacheMapValue(final String key, final Collection<Object> hKeys) {
return redisTemplate.opsForHash().multiGet(key, hKeys);
}
/**
* 获得缓存的基本对象列表
*
* @param pattern 字符串前缀
* @return 对象列表
*/
public Collection<String> keys(final String pattern) {
return redisTemplate.keys(pattern);
}
}
JWT工具类:JwtTokenUtil.java
import io.jsonwebtoken.*;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
@Configuration
@Component
@Slf4j
public class JwtTokenUtil {
/**
* token的头key
*/
public static final String AUTH_HEADER_KEY = "Authorization";
/**
* token前缀
*/
public static final String TOKEN_PREFIX = "Bearer ";
/**
* token 过期时间 30分钟
*/
public static final long EXPIRATION = 1000 * 60 * 30;
/**
* 加密的key(自己生成的任意值)
*/
public static final String APP_SECRET_KEY = "secret";
/**
* 生成token
* @return token字符串
*/
public static String createToken(Account account) {
Map<String, Object> claims = new HashMap<>();
claims.put("id", account.getId());
claims.put("username", account.getUsername());
claims.put("nickname", account.getNickname());
String token = Jwts
.builder()
.setId(account.getId())
.setClaims(claims)
.setIssuedAt(new Date())
.setExpiration(new Date(System.currentTimeMillis() + EXPIRATION))
.signWith(SignatureAlgorithm.HS256, APP_SECRET_KEY)
.compact();
return TOKEN_PREFIX +token;
}
/**
* 解析jwt
* @return 解析后的JWT Claims
*/
public static Claims parseJwt(String token) {
try {
return Jwts.parser().setSigningKey(APP_SECRET_KEY).parseClaimsJws(token.replace(TOKEN_PREFIX, "")).getBody();
} catch (Exception e) {
log.error("token exception : ", e);
}
return null;
}
/**
* 获取当前登录用户的ID
*
* @param token
* @return
*/
public static String getAccountId(String token) {
Claims claims = parseJwt(token);
return (String)claims.get("id");
}
/**
* 获取当前登录用户用户名
*
* @param token
* @return
*/
public static String getUsername(String token) {
Claims claims = parseJwt(token);
return (String)claims.get("username");
}
/**
* 检查token是否过期
*
* @param token token
* @return boolean
*/
public static boolean isExpiration(String token) {
Claims claims = parseJwt(token);
return claims.getExpiration().before(new Date());
}
public boolean validateToken(String token) {
try {
Jwts.parser().setSigningKey(APP_SECRET_KEY).parseClaimsJws(token);
return true;
} catch (SignatureException e) {
log.error("Invalid JWT signature: {}", e.getMessage());
} catch (MalformedJwtException e) {
log.error("Invalid JWT token: {}", e.getMessage());
} catch (ExpiredJwtException e) {
log.error("JWT token is expired: {}", e.getMessage());
} catch (UnsupportedJwtException e) {
log.error("JWT token is unsupported: {}", e.getMessage());
} catch (IllegalArgumentException e) {
log.error("JWT claims string is empty: {}", e.getMessage());
}
return false;
}
}
JWT权限拦截过滤器:JwtAuthenticationTokenFilter.java
import com.alibaba.fastjson.JSONObject;
import io.jsonwebtoken.Claims;
import jakarta.annotation.Resource;
import jakarta.servlet.FilterChain;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import lombok.extern.log4j.Log4j2;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import org.springframework.web.filter.OncePerRequestFilter;
import java.util.Objects;
/**
* token认证过滤器
* 作用:解析请求头中的token。并验证合法性
* 继承 OncePerRequestFilter 保证请求经过过滤器一次
*/
@Log4j2
@Component
public class JwtAuthenticationTokenFilter extends OncePerRequestFilter {
@Resource
private RedisCache redisCache;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain){
String token = request.getHeader(JwtTokenUtil.AUTH_HEADER_KEY);
if (StringUtils.hasText(token)) {
Claims claims = JwtTokenUtil.parseJwt(token);
if(claims!=null){
String accountId = (String)claims.get("id");
String redisKey = "login:" + accountId;
// 先转成JSON对象
JSONObject jsonObject = redisCache.getCacheObject(redisKey);
// JSON对象转换成Java对象
LoginUser loginUser = jsonObject.toJavaObject(LoginUser.class);
// redis中用户不存在
if (Objects.isNull(loginUser)) {
throw new RuntimeException("redis中用户不存在!");
}
// 将Authentication对象(用户信息、已认证状态、权限信息)存入 SecurityContextHolder
UsernamePasswordAuthenticationToken authenticationToken = new UsernamePasswordAuthenticationToken(loginUser, null, loginUser.getAuthorities());
SecurityContextHolder.getContext().setAuthentication(authenticationToken);
}
}
log.info("authentication :{}",SecurityContextHolder.getContext().getAuthentication());
//放行
try {
filterChain.doFilter(request, response); //放行,因为后面的会抛出相应的异常
}catch (Exception e){
e.printStackTrace();
}
}
}
鉴权Controller类:AuthApiControllerV1.java
import com.alibaba.fastjson2.JSONObject;
import com.hkbea.gbt.controller.api.v1.util.ApiControllerExceptionV1;
import com.hkbea.gbt.controller.api.v1.util.ResultVo;
import com.hkbea.gbt.model.Account;
import com.hkbea.gbt.on1on.On1onApiUtil;
import com.hkbea.gbt.security.core.LoginUser;
import com.hkbea.gbt.security.service.LoginService;
import com.hkbea.gbt.service.AccountService;
import jakarta.annotation.security.PermitAll;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.security.core.Authentication;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.bind.annotation.*;
import java.util.UUID;
@Log4j2
@RestController
@RequestMapping("/api/v1/auth")
public class AuthApiControllerV1 {
@Autowired
private LoginService loginService;
@Autowired
private AccountService accountService;
@PostMapping("login")
@PermitAll
public ResultVo login(@RequestBody JSONObject body) throws ApiControllerExceptionV1 {
String username = body.getString("username");
String password = body.getString("password");
if(username==null||(username=username.trim()).equals("")){
throw new ApiControllerExceptionV1("请输入正确的email账号");
}
if(password==null||(password=password.trim()).equals("")){
throw new ApiControllerExceptionV1("请输入password");
}
String jwt = loginService.login(username,password);
if(StringUtils.isEmpty(jwt)){
throw new ApiControllerExceptionV1("账号或密码错误");
}
return new ResultVo(ResultVo.SUCCESS,"登录成功",jwt);
}
@GetMapping("info")
@PreAuthorize("authenticated")
public ResultVo info(Authentication authentication) throws ApiControllerExceptionV1 {
LoginUser loginUser = (LoginUser) authentication.getPrincipal();
Account account = loginUser.getAccount();
JSONObject out = new JSONObject();
out.put("id",account.getId());
out.put("username",account.getUsername());
out.put("on1on_id",account.getOn1onId());
return new ResultVo(out);
}
/**
* 退出登录
*/
@RequestMapping(value="logout", method = {RequestMethod.DELETE})
@PreAuthorize("authenticated")
public ResultVo logout() throws ApiControllerExceptionV1{
if(loginService.logout()){
return new ResultVo(ResultVo.SUCCESS,"注销成功");
}
throw new ApiControllerExceptionV1("退出登录异常");
}
}
测试Controller:TestApiControllerV1.java
import com.alibaba.fastjson2.JSONObject;
import jakarta.annotation.security.PermitAll;
import lombok.extern.log4j.Log4j2;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.web.bind.annotation.*;
@Log4j2
@RestController
@RequestMapping("/api/v1/test")
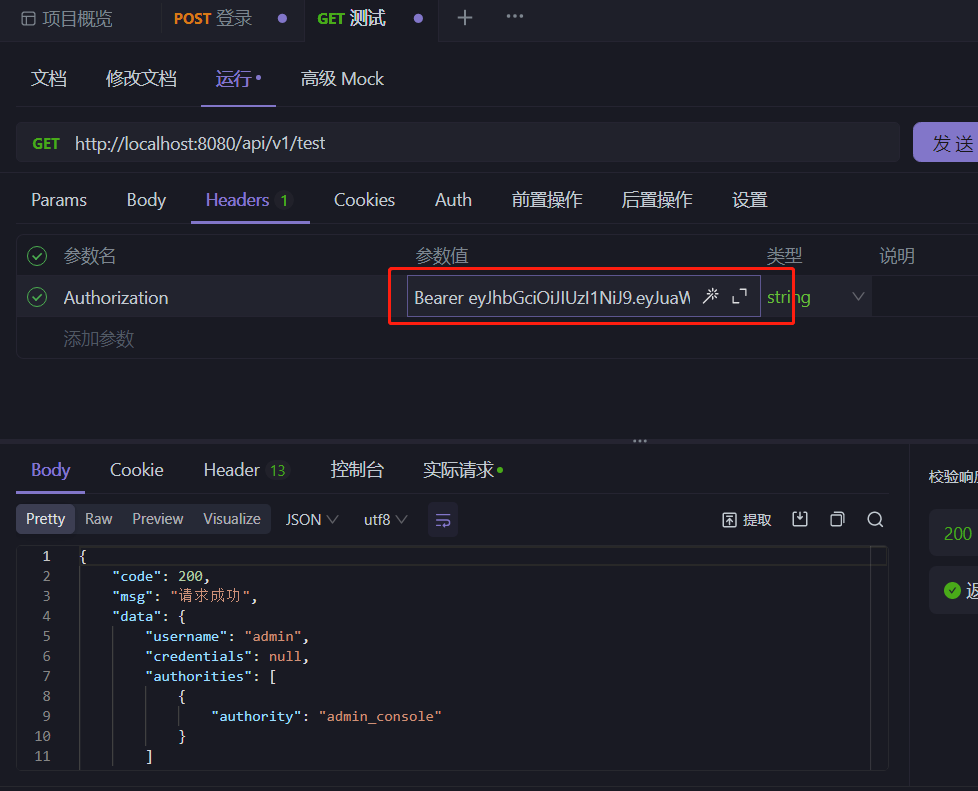
public class TestApiControllerV1 {
@GetMapping("")
@PermitAll
public ResultVo test(){
log.info("test");
JSONObject out = new JSONObject();
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
if(authentication!=null){
LoginUser loginUser = (LoginUser) authentication.getPrincipal();
System.out.println("username :"+loginUser.getAccount().getUsername());
System.out.println("凭证 :"+authentication.getCredentials());
System.out.println("权限 :"+authentication.getAuthorities());
out.put("username",loginUser.getAccount().getUsername());
out.put("credentials",authentication.getCredentials());
out.put("authorities",authentication.getAuthorities());
}
return new ResultVo(out);
}
}
MySQL测试数据脚本:
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for account
-- ----------------------------
DROP TABLE IF EXISTS `account`;
CREATE TABLE `account` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`nickname` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of account
-- ----------------------------
INSERT INTO `account` VALUES ('5a07d8d95b9a46179d10a67f3765d363', 'admin', '$2a$10$MKzkFJJLuGMWO1eL9YuS9uinjq6H4Kalf9MzDxIFPQ4.fV9IKHNCC', '管理员');
INSERT INTO `account` VALUES ('85a223c1a519463e9e8de3a096818e6a', 'user', '123456', '普通用户');
-- ----------------------------
-- Table structure for account_role
-- ----------------------------
DROP TABLE IF EXISTS `account_role`;
CREATE TABLE `account_role` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`account_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`role_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of account_role
-- ----------------------------
INSERT INTO `account_role` VALUES ('eb014d68525849c29a5998e7133c1db9', '5a07d8d95b9a46179d10a67f3765d363', '28fb6f155b3b49e38a7241893b8d03f2');
-- ----------------------------
-- Table structure for permission
-- ----------------------------
DROP TABLE IF EXISTS `permission`;
CREATE TABLE `permission` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of permission
-- ----------------------------
INSERT INTO `permission` VALUES ('80ad0fd1296f48a8bdd98ec700947c63', 'admin_console');
-- ----------------------------
-- Table structure for role
-- ----------------------------
DROP TABLE IF EXISTS `role`;
CREATE TABLE `role` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of role
-- ----------------------------
INSERT INTO `role` VALUES ('28fb6f155b3b49e38a7241893b8d03f2', '管理员');
-- ----------------------------
-- Table structure for role_permission
-- ----------------------------
DROP TABLE IF EXISTS `role_permission`;
CREATE TABLE `role_permission` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`role_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`permission_id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of role_permission
-- ----------------------------
INSERT INTO `role_permission` VALUES ('28e1307e38124275b9e2d428adee3e0b', '28fb6f155b3b49e38a7241893b8d03f2', '80ad0fd1296f48a8bdd98ec700947c63');
SET FOREIGN_KEY_CHECKS = 1;
测试结果: